
تنفّذ وحدة المعالجة المركزية التعليمات على القيم الموجودة في المسجّلات Registers، إذ يوضّح المثال الآتي أولًا ضبط R1 على القيمة 100 وتحميل القيمة من موقع الذاكرة 0x100 إلى R2 وجمع القيمتين، ثم وضع النتيجة في R3، وأخيرًا تخزين القيمة الجديدة 110 في R4.
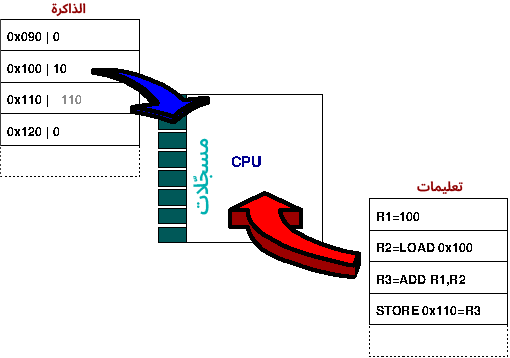
يتكون الحاسوب من وحدة معالجة مركزية Central Processing Unit -أو CPU اختصارًا- متصلة بالذاكرة، إذ توضّح الصورة السابقة المبدأ العام لجميع عمليات الحاسوب، كما تنفّذ وحدة المعالجة المركزية التعليمات المقروءة من الذاكرة، وهناك نوعان من هذه التعليمات هما:
- التعليمات التي تحمّل القيم من الذاكرة إلى المسجلات وتخزّن القيم من المسجلات إلى الذاكرة.
- التعليمات التي تُشغَّل على القيم المخزَّنة في المسجّلات مثل جمع أو طرح أو ضرب أو قسمة قيمتين موجودتين في مسجلين، أو إجراء العمليات الثنائية and و or و xor وغيرها، أو إجراء عمليات حسابية أخرى، مثل الجذر التربيعي و sin و cos و tan وغيرها.
لذا نجمع في مثالنا ببساطة العدد 100 مع قيمة مُخزَّنة في الذاكرة ونخزّن النتيجة الجديدة في الذاكرة.
التفريع Branching
يُعَدّ التفريع عمليةً مهمةً لوحدة المعالجة المركزية، وذلك بغض النظر عن عمليتي التحميل أو التخزين، إذ تحتفظ وحدة المعالجة المركزية داخليًا بسجل للتعليمة التالية التي ستنفَّذ في مؤشر التعليمات Instruction Pointer، بحيث يُزاد هذا المؤشر ليؤشّر إلى التعليمة التالية تسلسليًا، إذ ستتحقق التعليمة الفرعية مما إذا كان لمسجل معيّن القيمة صفر، أو تتحقق من وجود من ضبط راية flag ما. فإذا كان الأمر كذلك، فسيُعدَّل المؤشر ليؤشّر إلى عنوان مختلف، وبالتالي ستكون التعليمة التالية للتنفيذ من جزء مختلف من البرنامج، وهذه هي الطريقة التي تعمل بها الحلقات وتعليمات القرار.
يمكن مثلًا تنفيذ التعليمة if (x==0) من خلال إيجاد ناتج تطبيق عملية or على اثنين من المسجلات، أحدهما يحمل القيمة x والآخر يحمل القيمة صفر، فإذا كانت النتيجة صفرًا، فستكون المقارنة صحيحة، أي أنّ جميع بتات x أصفار ويجب تنفيذ جسم التعليمة، وإلّا فستتجاوز التعليمة الفرعية هذه الشيفرة.
الدورات
جميعنا على دراية بسرعة الحاسوب المعطاة بالميجاهرتز أو الجيجاهرتز التي تقابل ملايين أو آلاف الملايين من الدورات في الثانية، ويسمى ذلك بسرعة الساعة Clock Speed لأنها السرعة التي تنبض بها ساعة الحاسوب الداخلية، إذ تُستخدَم النبضات ضمن المعالج لإبقائه متزامنًا داخليًا، ويمكن البدء بعملية أخرى في كل لحظة أو نبضة.
جلب التعليمة وفك تشفيرها وتنفيذها وتخزين نتيجتها
يتكون تنفيذ تعليمة واحدة من دورة معينة من الأحداث، وهي الجلب وفك التشفير والتنفيذ والتخزين، إذ يجب على وحدة المعالجة المركزية تطبيق الخطوات التالية لتنفيذ تعليمة add السابقة مثلًا:
- الجلب Fetch: الحصول على التعليمات من الذاكرة إلى المعالج.
- فك التشفير Decode: فك تشفير ما يجب أن تفعله داخليًا، أي الجمع في هذه الحالة.
- التنفيذ Execute: أخذ القيم من المسجلات وجمعها.
- التخزين Store: تخزين النتيجة في مسجل آخر، كما يمكن رؤية مصطلح انتهاء Retiring التعليمة.
نظرة داخلية إلى وحدة المعالجة المركزية
تحتوي وحدة المعالجة المركزية داخليًا على العديد من المكونات الفرعية المختلفة التي تطبّق كلًا من الخطوات المذكورة سابقًا، كما يمكن أن تحدث جميعها بصورة مستقلة عن بعضها البعض، وهي مشابهة لخط الإنتاج في المصانع، حيث توجد العديد من المحطات ولكل خطوة مَهمة معينة لأدائها، ثم يمكنه تمرير النتائج إلى المحطة التالية وأخذ مدخلات جديدة للعمل عليها.
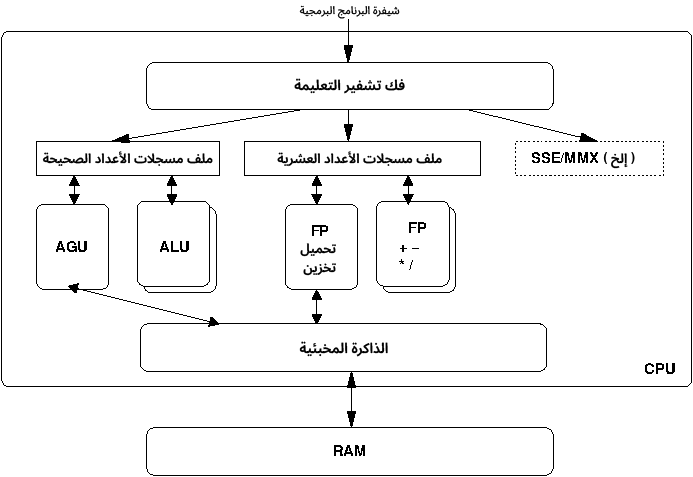
تتكون وحدة المعالجة المركزية من العديد من المكونات الفرعية المختلفة، وتطبّق كل منها مهمةً مُخصَّصةً.
توضِّح الصورة السابقة مخططًا بسيطًا لبعض الأجزاء الرئيسية لوحدة المعالجة المركزية الحديثة، حيث يمكنك رؤية التعليمات تأتي ثم يفك المعالج تشفيرها؛ كما تحتوي وحدة المعالجة المركزية على نوعين رئيسيين من المسجّلات، هما مسجلات العمليات الحسابية الخاصة بالأعداد الصحيحة ومسجلات العمليات الحسابية الخاصة بالأعداد العشرية.
تُعَدّ الأعداد العشرية Floating Point طريقةً لتمثيل الأعداد ذات المنزلة العشرية بصيغة ثنائية، ويجري التعامل معها بطريقة مختلفة ضمن وحدة المعالجة المركزية، كما تُعَدّ المسجلات MMX (توسع الوسائط المتعددة Multimedia Extension) و SSE (مجرى بيانات متعددة لتعليمة مفردة Streaming Single Instruction Multiple Data) أو Altivec مسجلات مماثلة للمسجلات الخاصة الأعداد العشرية.
يُعَدّ ملف المسجلات Register File اسمًا يجمع جميع المسجلات الموجودة ضمن وحدة المعالجة المركزية، وتوجد ضمنه أجزاء وحدة المعالجة المركزية التي تنفّذ كل العمل، إذ تحمّل المعالجات أو تخزّن قيمةً في مسجل أو من مسجل إلى الذاكرة، أو تنفّذ بعض العمليات على القيم الموجودة في المسجلات كما قلنا سابقًا.
تُعَدّ وحدة الحساب والمنطق Arithmetic Logic Unit -أو ALU اختصارًا- قلب عمليات وحدة المعالجة المركزية، إذ تأخذ القيم من المسجلات وتنفّذ أيًا من العمليات المتعددة التي تستطيع وحدة المعالجة المركزية تنفيذها، كما تحتوي جميع المعالجات الحديثة على عدد من وحدات ALU، بحيث يمكن لكل منها العمل بصورة مستقلة، وتحتوي المعالجات مثل المعالج بنتيوم Pentium على وحدات ALU سريعة ووحدات ALU بطيئة، إذ تكون الوحدات السريعة أصغر حجمًا، لذا يمكنك استخدام المزيد منها على وحدة المعالجة المركزية، ولكن يمكنك تنفيذ العمليات الأكثر شيوعًا فقط؛ أما وحدات ALU البطيئة، فيمكنها تنفيذ جميع العمليات ولكنها تكون أكبر حجمًا.
تعالِج وحدة إنشاء العناوين Address Generation Unit -أو AGU اختصارًا- التواصل مع الذاكرة المخبئية Cache Memory والذاكرة الرئيسية لجلب القيم إلى المسجلات لكي تعمل وحدة ALU، ثم استعادة القيم من المسجلات إلى الذاكرة الرئيسية، كما تحتوي مسجلات الأعداد العشرية على المفاهيم نفسها، ولكنها تستخدِم مصطلحات مختلفةً قليلًا لمكوناتها.
استخدام خط الأنابيب
تُعَدّ عملية وحدة ALU التي تجمع قيم المسجلات منفصلةً تمامًا عن عملية وحدة AGU التي تكتب القيم في الذاكرة، إذ لا يوجد سبب يمنع وحدة المعالجة المركزية من تطبيق هاتين العمليتين معًا في وقت واحد، كما توجد عدة وحدات ALU في النظام والتي يمكن أن تعمل كل منها على تعليمات منفصلة.
يمكن لوحدة المعالجة المركزية تنفيذ بعض عمليات الأعداد العشرية باستخدام منطق الأعداد العشرية أثناء تشغيل تعليمات الأعداد الصحيحة أيضًا، إذ تسمى هذه العملية باستخدام خط الأنابيب Pipelining، ويشار إلى المعالج الذي يمكنه تطبيق هذه العملية بأن له معمارية عددية فائقة Superscalar Architecture، إذ تُعَدّ جميع المعالجات الحديثة معالجات عدديةً فائقةً، ويحتوي أيّ معالج حديث على أكثر من أربع مراحل يمكنه استخدامها ضمن خط أنابيب، وكلما زاد عدد المراحل التي يمكن تنفيذها في الوقت نفسه، زاد عمق خط الأنابيب.
يمكن تشبيه خط الأنابيب بأنبوب مملوء بكرات زجاجية، باستثناء أن هذه الكرات هي تعليمات وحدة المعالجة المركزية، إذ ستضع الكرات الزجاجية في نهاية واحدة، بحيث تضعها واحدةً تلو الأخرى -أي كرة لكل نبضة ساعة- حتى تملأ الأنبوب، وستنتقل كل كرة زجاجية -أو تعليمة- تدفعها للداخل إلى الموضع التالي بمجرد أن يمتلئ الأنبوب مع سقوط كرة في النهاية التي تمثّل النتيجة.
تؤدي التعليمات الفرعية إلى إحداث فوضى في هذا النموذج، إذ يمكن أن تتسبب أو لا تتسبب في بدء التنفيذ من مكان مختلف، فإذا أردت استخدام خط الأنابيب، فسيتعين عليك تخمين الاتجاه الذي ستتجه فيه التعليمة الفرعية حتى تعرف التعليمات التي يجب إحضارها إلى خط الأنابيب، فإذا خمّنت وحدة المعالجة المركزية ذلك بصورة صحيحة، فسيسير كل شيء على ما يرام، إذ تستخدِم المعالجات مثل معالج بنتيوم ذاكرة تخزين مؤقت Trace Cache لتعقب مسار التعليمات الفرعية، حيث يمكن في كثير من الأحيان أن تخمّن الطريق الذي ستذهب إليه التعليمة الفرعية من خلال تذكر نتائجها السابقة، فإذا تذّكرتَ نتيجة التعليمة الفرعية الأخيرة في حلقة تتكرر 100 مرة مثلًا، فستكون على صواب 99 مرة، لأن المرة الأخيرة فقط ستستمر في البرنامج فعليًا؛ بينما إذا جرى تخمين المعالج بطريقة غير صحيحة، فهذا يعني أنّ المعالج قد أهدر كثيرًا من الوقت ويجب عليه مسح خط الأنابيب والبدء من جديد.
يشار إلى هذه العملية عادةً باسم تفريغ خط الأنابيب Pipeline Flush وهي مماثلة للحاجة إلى التوقف وإفراغ كل الكرات من الأنبوب، كما تتكوّن عملية تخمين التعليمة الفرعية Branch Prediction من تفريغ خط الأنابيب وأخذ التخمين أو عدم الأخذ به وفتحات تأخير التعليمة الفرعية branch delay slots.
إعادة الترتيب
إذا كانت وحدة المعالجة المركزية هي الأنبوب، فسنكون لك الحرية في إعادة ترتيب الكرات ضمنه طالما أنها تخرج من نهايته بالترتيب نفسه الذي وضعتَها فيه، إذ نسمي ذلك بترتيب البرنامج Program Order لأنه ترتيب التعليمات المُعطَى في البرنامج الحاسوبي، كما يمكنك الاطلاع على المثال التالي الذي يمثل إعادة ترتيب المخزن المؤقت Buffer:
1: r3 = r1 * r2 2: r4 = r2 + r3 3: r7 = r5 * r6 4: r8 = r1 + r7
افترض مجرى التعليمات الموضح سابقًا، إذ يجب على التعليمة 2 انتظار اكتمال التعليمة 1 قبل أن تبدأ، وهذا يعني أنّ خط الأنابيب يجب عليه التوقف أثناء انتظار القيمة المراد حسابها، كما تعتمد التعليمتان 3 و 4 على قيمة r7، ولكن التعليمتان 2 و 3 لا تعتمدان على بعضهما البعض أبدًا، وهذا يعني أنهما يعملان في مسجلات منفصلة تمامًا، فإذا بدّلنا بين التعليمتين 2 و 3، فسنحصل على ترتيب أفضل لخط الأنابيب، إذ يمكن أن ينفّذ المعالج عملًا مفيدًا بدلًا من انتظار اكتمال خط الأنابيب للحصول على نتيجة التعليمة السابقة.
يمكن أن تتطلب التعليمات بعض الأمان حول كيفية ترتيب العمليات عند كتابة شيفرة منخفضة المستوى، إذ نطلق على هذا المتطلب دلالات الذاكرة Memory Semantics، فإذا أردت اكتساب الدلالات Acquire Semantics، فهذا يعني أنه يجب عليك التأكد من إكمال نتائج جميع التعليمات السابقة للتعليمة الحالية، وإذا أردت تحرير الدلالات Release Semantics، فهذا يعني أنّ جميع التعليمات بعد هذه التعليمة يجب أن ترى النتيجة الحالية.
توجد دلالات أخرى أكثر صرامة وهي حاجز الذاكرة Memory Barrier أو سور الذاكرة Memory Fence الذي يتطلب أن تكون العمليات مرتبطةً بالذاكرة قبل المتابعة، كما يضمن المعالج هذه الدلالات في بعض المعماريات، بينما يجب أن تحددها بصورة صريحة في المعماريات الأخرى، ولا يحتاج معظم المبرمجين إلى القلق بشأنها على الرغم من أنك قد تصادفها.
معمارية CISC ومعمارية RISC
يمكن تقسيم معماريات الحاسوب إلى معمارية حاسوب مجموعة التعليمات المعقدة Complex Instruction Set Computer -أو CISC اختصارًا- ومعمارية حاسوب مجموعة التعليمات المُخفَّضة Reduced Instruction Set Computer أو RISC اختصارًا.
لاحظ أننا في المثال الأول من مقالنا حمّلنا القيم صراحةً في المسجلات وأجرينا عملية الجمع، ثم خزّنا القيمة الناتجة المحفوظة في مسجل آخر في الذاكرة، إذ يُعَدّ ذلك مثالًا عن نهج RISC للحوسبة الذي يشمل تنفيذ العمليات على القيم الموجودة في المسجلات وتحميل القيم وتخزينها بصورة صريحة من الذاكرة وإليها، كما يمكن أن يكون نهج CISC مجرد تعليمات مفردة تأخذ قيمًا من الذاكرة وتنفذ عملية الجمع داخليًا ثم تكتب النتيجة، وهذا يعني أنّ التعليمات يمكن أن تستغرق عدة دورات، ولكن كلا النهجين يحققان في النهاية الهدف نفسه.
تُعَدّ جميع المعماريات الحديثة معماريات RISC حتى معمارية إنتل بنتيوم Intel Pentium الأكثر شيوعًا والتي تهدم التعليمات داخليًا إلى تعليمات فرعية بأسلوب RISC داخل الشريحة قبل التنفيذ، بالرغم من وجود مجموعة تعليمات مصنَّفة على أنها CISC، وهناك عدة أسباب لذلك وهي:
- تجعل معمارية RISC البرمجة بلغة التجميع Assembly أكثر تعقيدًا، نظرًا لأن جميع المبرمجين تقريبًا يستخدِمون لغات عالية المستوى ويتركون العمل الشاق لإنتاج شيفرة التجميع للمصرّف Compiler، وبالتالي ستتفوق المزايا الأخرى على هذا العيب.
- بما أنّ التعليمات الموجودة في معالج RISC أبسط، فهناك مساحة أكبر ضمن شريحة المسجلات، إذ تُعَدّ المسجلات أسرع أنواع الذواكر كما نعلم من تسلسل الذواكر الهرمي، ويجب في النهاية تنفيذ جميع التعليمات على القيم المحفوظة في المسجلات، لذا ستؤدي زيادة عدد المسجلات إلى أداء أعلى عند تكافؤ جميع الأشياء الأخرى.
- بما أنّ جميع التعليمات تُنفَّذ في الوقت نفسه، فسيكون استخدام خطوط الأنابيب ممكنًا، وكما نعلم أنّ استخدام خط الأنابيب يتطلب تدفقات من التعليمات باستمرار إلى المعالج، لذلك إذا استغرقت بعض التعليمات وقتًا طويلًا جدًا دون أن تتطلب التعليمات الأخرى ذلك، فسيصبح خط الأنابيب معقدًا ليكون فعّالًا.
معمارية EPIC
يُعَدّ معالج إيتانيوم Itanium مثالًا على معمارية معدَّلة تسمى الحوسبة الصريحة للتعليمات الفرعية Explicitly Parallel Instruction Computing.
ناقشنا سابقًا كيف أنّ المعالجات الفائقة لها خطوط أنابيب بها العديد من التعليمات في الوقت نفسه ضمن أجزاء مختلفة من المعالج، إذ يمكن تحقيق ذلك من خلال إعطاء التعليمات للمعالج بالترتيب الذي يمكن أن يحقق أفضل استفادة من العناصر المتاحة في وحدة المعالجة المركزية، وقد كان تنظيم مجرى التعليمات الواردة تقليديًا مهمة العتاد، إذ يصدر البرنامج التعليمات بطريقة تسلسلية، ويجب أن ينظر المعالج إلى الأمام ويحاول اتخاذ قرارات حول كيفية تنظيم التعليمات الواردة.
الفكرة وراء معمارية EPIC هي أنّ هناك مزيد من المعلومات المتاحة على مستويات أعلى والتي يمكن أن تجعل هذه القرارات أفضل مما يفعله المعالج، ويؤدي تحليل مجرًى من تعليمات لغة التجميع -كما تفعل المعالجات الحالية- إلى فقدان الكثير من المعلومات التي قدّمها المبرمج في الشيفرة البرمجية الأصلية.
فكر في الأمر على أنه الفرق بين دراسة مسرحية لشكسبير وقراءة نسخة ملاحظات الجرف Cliff's Notes من المسرحية نفسها، فكلاهما يمنحك النتيجة نفسها، ولكن النسخة الأصلية تحتوي على جميع أنواع المعلومات الإضافية التي تحدد المشهد وتعطيك فهمًا جيدًا للشخصيات، وبالتالي يمكن نقل منطق ترتيب التعليمات من المعالج إلى المصرّف، وهذا يعني أنّ مطوِّري المصرّفات يجب أن يكونوا أذكى في محاولة العثور على أفضل ترتيب للشيفرة البرمجية للمعالج، كما يجب تبسيط المعالج كثيرًا، إذ نُقِل الكثير من عمله إلى المصرِّف.
يوجد مصطلح آخر غالبًا ما يُستخدَم مع معمارية EPIC وهو عالم التعليمات الطويلة جدًا Very Long Instruction World -أو VLIW اختصارًا-، إذ تُوسَّع كل تعليمة للمعالج لإخباره بالمكان الذي يجب أن ينفّذ فيه التعليمة في وحداته الداخلية، وتكمن مشكلة هذا الأسلوب في أنّ الشيفرة البرمجية تعتمد كليًا على طراز المعالج الذي صُرِّفت الشيفرة البرمجية من أجله، كما تُجري الشركات دائمًا مراجعات على العتاد، وتجعل العملاء يعيدون تصريف تطبيقاتهم في كل مرة، مما جعل صيانة مجموعة من الشيفرات البرمجية الثنائية المختلفة أمرًا غير عملي.
تحل معمارية EPIC هذه المشكلة بطريقة علوم الحاسوب المعتادة من خلال إضافة طبقة من التجريد، كما تنشئ معمارية EPIC عرضًا مبسطًا مع بعض الوحدات الأساسية مثل الذاكرة ومسجّلات الأعداد الصحيحة والعشرية بدلًا من التحديد الصريح للجزء الدقيق من المعالج الذي يجب أن تنفّذ التعليمات عليه.
ترجمة -وبتصرُّف- للقسم The CPU من الفصل Computer Architecture من كتاب Computer Science from the Bottom Up لصاحبه Ian Wienand.
تعليقات
إرسال تعليق